Abstract
Prediction of protein subcellular multisite localization using a new feature extraction method
Author(s): L.Y. Wang, D. Wang and Y.H. ChenA basic problem of proteomics is identifying the subcellular locations of a protein. One factor making the problem more complicated is that some proteins may simultaneously exist in two or more than two subcellular locations. To improve multisite prediction quality, it is necessary to use effective feature extraction methods. Here, we developed a new feature extraction method based on the pK value and frequencies of amino acids to represent a protein as a real values vector. Using this novel feature extraction method, the multi-label k-nearest neighbors (ML-KNN) algorithm and setting different weights into different attributes’ ML-KNN, known as wML-KNN, were employed to predict multiplex protein subcellular locations. The best overall accuracy rate on dataset S1 from the predictor of Virus-mPLoc was 59.92 and 86.04% on dataset S2 from Gpos-mPLoc, respectively.
Impact Factor an Index

Google scholar citation report
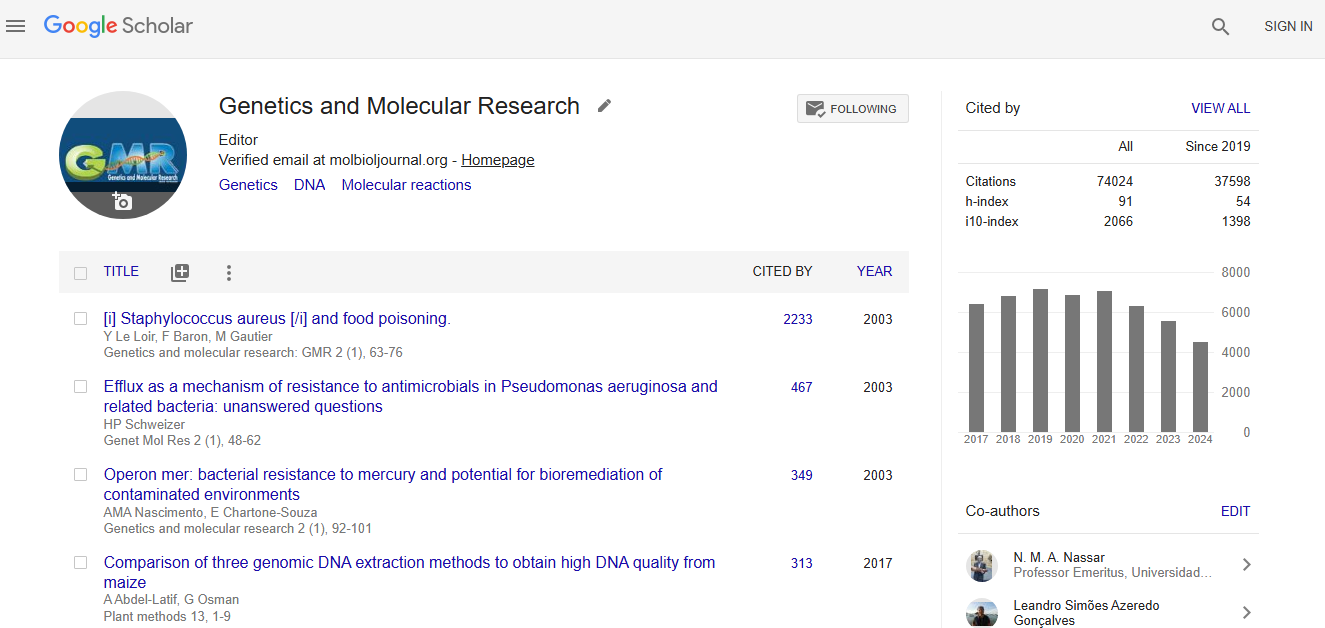
Citations : 74024
Genetics and Molecular Research received 74024 citations as per google scholar report