Abstract
Predicting enzyme class from protein structure using Bayesian classification
Author(s): Luiz C. Borro, Stanley R.M. Oliveira, Michel E.B. Yamagishi, Adaulto L. Mancini, Jos├?┬® G. Jardine, Ivan Mazoni, Edgard H. dos Santos, Roberto H. Higa, Paula R. Kuser and Goran NeshichPredicting enzyme class from protein structure parameters is a challenging problem in protein analysis. We developed a method to predict enzyme class that combines the strengths of statistical and data-mining methods. This method has a strong mathematical foundation and is simple to implement, achieving an accuracy of 45%. A comparison with the methods found in the literature designed to predict enzyme class showed that our method outperforms the existing methods.
Impact Factor an Index

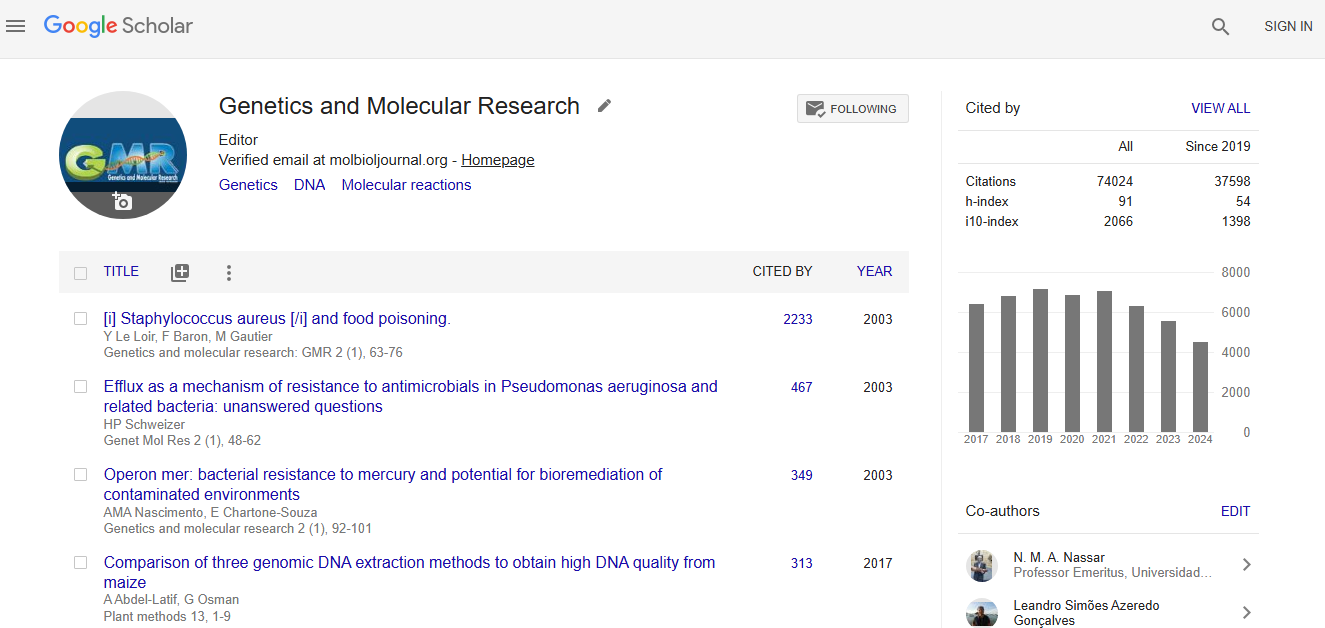
Google scholar citation report
Citations : 74024
Genetics and Molecular Research received 74024 citations as per google scholar report