Abstract
Characterization of ESTs from black locust for gene discovery and marker development
Author(s): J.X. Wang, C. Lu, C.Q. Yuan, B.B. Cui, Q.D. Qiu, P. Sun, R.Y. Hu, D.C. Wu, Y.H. Sun and Y. LiBlack locust (Robinia pseudoacacia L.) is an ecologically and economically important species. However, it has relatively underdeveloped genomic resources, and this limits gene discovery and marker-assisted selective breeding. In the present study, we obtained large-scale transcriptome data using a next-generation sequencing platform to compensate for the lack of black locust genomic information. Increasing the amount of transcriptome data for black locust will provide a valuable resource for multi-gene phylogenetic analyses and will facilitate research on the mechanisms whereby conserved genes and functions are maintained in the face of species divergence. We sequenced the black locust transcriptome from a cDNA library of multiple tissues and individuals on an Illumina platform, and this produced 108,229,352 clean sequence reads. The high-quality overlapping expressed sequence tags (ESTs) were assembled into 36,533 unigenes, and 4781 simple sequence repeats were characterized. A large collection of high-quality ESTs was obtained, de novo assembled, and characterized. Our results markedly expand the previous transcript catalogues of black locust and can gradually be applied to black locust breeding programs. Furthermore, our data will facilitate future research on the comparative genomics of black locust and related species.
Impact Factor an Index

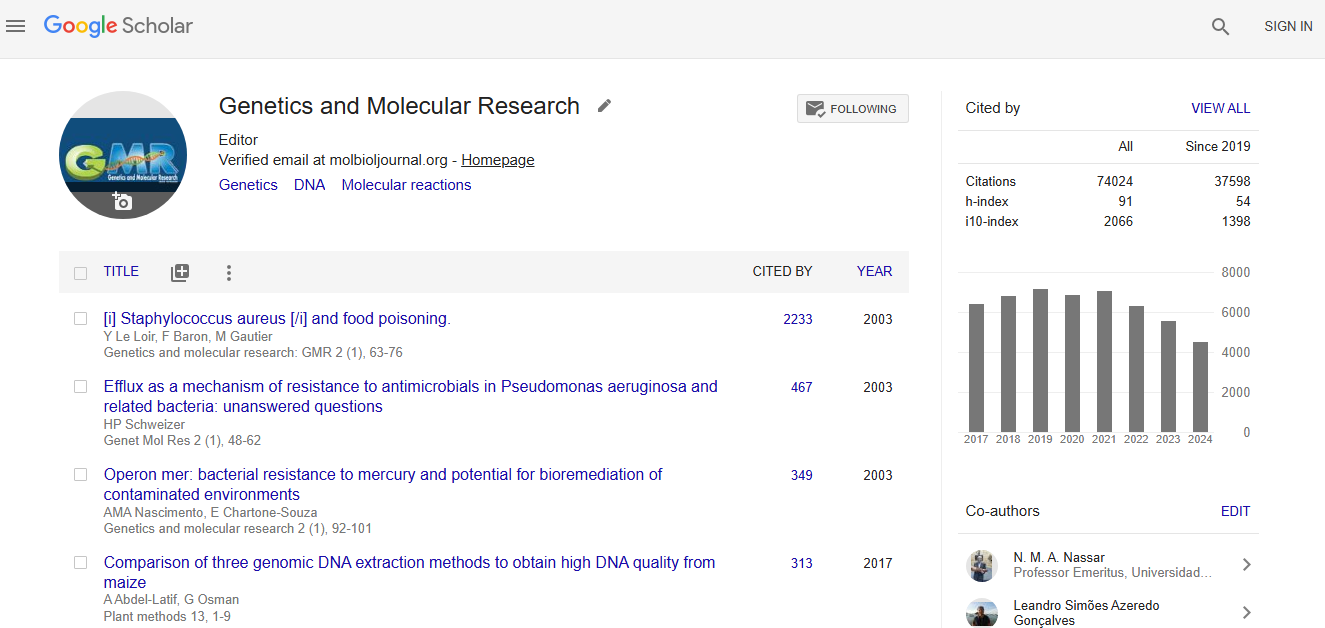
Google scholar citation report
Citations : 74024
Genetics and Molecular Research received 74024 citations as per google scholar report